TRAIL
TRAIL (Tokyo Robotics and AI Lab) は東京大学松尾・岩澤研究室のサブグループです. 実世界での知能の実現を目指して,ロボット学習を中心とした研究開発活動を行なっています.






プロジェクト
ロボットナビゲーションにおける継続学習
Improving policy adaptation for robot learning
自己修復型3Dプリンタにおける非理想的固定点
本研究では、x軸およびy軸上において2つの非理想的なタイミングプーリーを有するプリンタが、フィードバックを用いずに自己修復を達成できないことを数学的に証明することを目的とする。
遅延を伴うシステムに対する連続時間ラグランジュ緩和
双対変数の有用なヒューリスティック表現を見つけることを目的とする.これにより、他の問題の初期推定値を見つける手助けになる.

ロボットショーケース
当研究室には、最先端のロボット学習技術をロボットに実装するロ
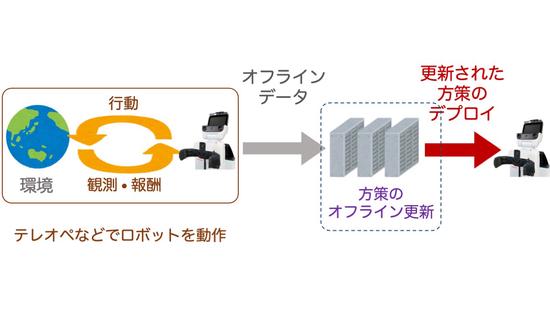
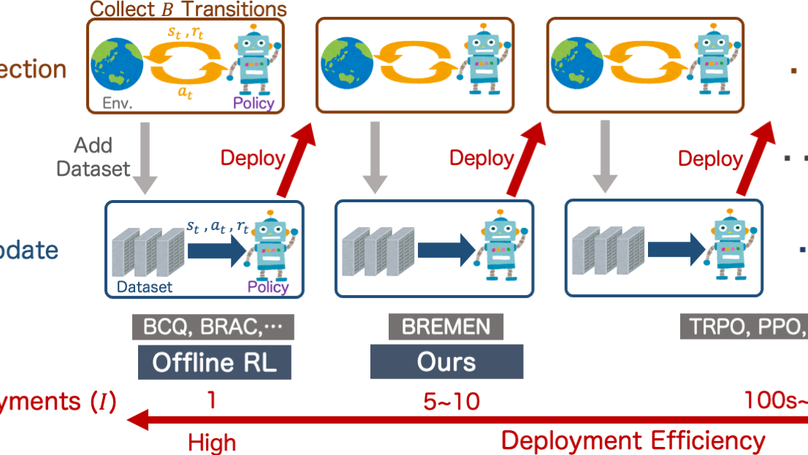
オフラインデータを利用したロボット学習アルゴリズムの開発
ロボットが動作することで蓄積されるログを制御の学習に活用するアルゴリズムを開発しています

強化学習における方策や環境の定量化
強化学習アルゴリズムでの方策や環境の定量化・比較に関する研究を行なっています

シミュレーションと直感的遠隔操作を活用したロボット学習による持続可能なブドウ栽培のための適応型剪定ロボット基盤の創成 (JST SICORP DEMETER)
本プロジェクトでは、日本、フランス、ドイツの研究チームが国際共同研究を通じて、持続可能な農業の実現に向けた革新的なロボット技術の開発に取り組むとともに、ロボット学習や遠隔操作技術を活用し、多様な分野への応用性を広げることを目指します。

代表論文
新着論文
講義

人工知能応用プロジェクト(2024年度Sセメスター)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

人工知能応用プロジェクト(2023年度Aセメスター)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

人工知能応用プロジェクト(2023年度Sセメスター)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

人工知能応用プロジェクト(2022年度Aセメスター)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

人工知能応用プロジェクト(2022年度夏学期)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

深層強化学習オータムセミナー2021
2021年11月から12月にかけて深層強化学習に関する短期セミナーを実施します

人工知能応用プロジェクト(2021年度冬学期)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します

人工知能応用プロジェクト(2021年度夏学期)
人工知能技術をロボット制御に応用するプロジェクト型演習を実施します
深層学習・ディープラーニング基礎講座(2021年度夏学期)
2021年度夏学期に,深層学習研究の基礎を身につけるための講座を開講します.

深層強化学習スプリングセミナー2021
2021年2月から3月にかけて深層強化学習に関する短期セミナーを実施します

深層強化学習サマースクール2020
2020年度夏期に深層強化学習に関する短期セミナーを実施します
連絡先
- trail@weblab.t.u-tokyo.ac.jp
- 113-0033 東京都 文京区 本郷 5-24-5 ナガセ本郷ビル9階